Sokratis Papadopoulos data | urban | policy
Expression of emotions in literature through big data

In this post, inspired by this very interesting work, I process Google 1-grams to analyze patterns in English and German 20th century literature emotions.
I try to replicate the paper’s results and extend the method to other languages. I am showing how to process large-scale text data using functional programming and without loading entire files in memory.
Let’s get started!
First, we pull the English emotion-related lexicons from the WordNet-Affect project. Then, we call the Google Translate API to translate the lexicons in German.
translator = Translator()
listOfEmotions = ['anger', 'disgust', 'fear', 'joy', 'sadness', 'surprise', 'normalize']
emotionD_eng={}
emotionD_ger={}
# Load all WordNetAffect emotion lists and store them in a dictionary from kylehg's github sentiment
# analysis repo: https://github.com/kylehg/sentiment-analysis/tree/master/lexicons/wordnet
for emotion in listOfEmotions:
if emotion not in 'normalize':
words = []
source = urllib2.urlopen(r"https://raw.githubusercontent.com/kylehg/sentiment-analysis/master/lexicons/wordnet/"
+ emotion +".txt")
for line in source:
words.append(line.split()[1:])
# store english words in dictionary
words = list(itertools.chain(*words))
emotionD_eng[emotion] = words
# translate and store german words
try:
words_ger = map(lambda x: unicodedata.normalize('NFD', translator.translate(x, dest='de').text).encode('ascii', 'ignore').lower(), words)
except ValueError:
pass
emotionD_ger[emotion] = words_ger
else:
emotionD_eng[emotion] = [[u'the']]
emotionD_ger[emotion] = [[u'das']]
Now we have two dictionaries, an English and a German, including the words associated with all six emotions we analyze. Let’s download the 1-grams included in all the books published during the 20th century.
# Create directories to store the .csv files
os.mkdir('eng')
os.mkdir('ger')
# Create directories to store the processed .pkl files
os.mkdir('pickledEmotions')
os.mkdir('pickledEmotions/eng')
os.mkdir('pickledEmotions/ger')
# Download Google 1-grams
for num in range(10):
# English 1-grams
url = "http://storage.googleapis.com/books/ngrams/books/googlebooks-eng-all-1gram-20090715-"+str(num)+".csv.zip"
filename = url.split("/")[-1]
with open(filename, "wb") as f:
r = requests.get(url)
f.write(r.content)
# German 1-grams
url = "http://storage.googleapis.com/books/ngrams/books/googlebooks-ger-all-1gram-20090715-"+str(num)+".csv.zip"
filename = url.split("/")[-1]
with open(filename, "wb") as f:
r = requests.get(url)
f.write(r.content)
# Unzip data and move to directory
for fileName in os.listdir('.'):
if '.zip' in fileName:
zip_ref = zipfile.ZipFile(fileName, 'r')
zip_ref.extractall()
zip_ref.close()
for csvFile in glob.glob('*.csv'):
if '-eng-' in csvFile:
shutil.move(csvFile, "eng/"+csvFile)
else:
shutil.move(csvFile, "ger/"+csvFile)
Next I write a couple of map and filter functions to process our data efficiently. Along with the emotional words I count the word “the” (ger: “das”) occurrences as a normalization factor.
# 'the' is the normalization factor
listOfEmotions = ['anger', 'disgust', 'fear', 'joy', 'sadness', 'surprise', 'the']
# load pickled emotion words dictionaries
emotionD_eng, emotionD_ger = cPickle.load(open('wordNetdicts.pkl', 'r'))
# Aggregate emotional words by year
def mapper(row):
return unicodedata.normalize('NFD', row['word'].decode('utf-8')), int(row['year']), int(row['counts'])
def mapper2(row):
return (row[1], row[2])
aggrEmotDic={}
# Process
for lang in ['eng', 'ger']:
if lang == 'eng':
# Due to change in encoding in compute environment
emotionD_eng['the'] = [[u'the']]
emotionDic = emotionD_eng
else:
emotionD_ger['the'] = [[u'das']]
emotionDic = emotionD_ger
for emotion in listOfEmotions:
def filterer(filt):
# select 20th centrury emotional words
if (filt[1]<=2000)&(filt[1]>=1900)&(filt[0] in emotionDic[emotion]):
return filt
counts = []
counter = 1
os.chdir(os.getcwd() + '/' + lang)
for csvFile in glob.glob('*.csv'):
with open(csvFile, 'rb') as csvfile:
reader = csv.DictReader(csvfile, fieldnames=['word', 'year', 'counts', 'page', 'volume'],
delimiter='\t', quoting=csv.QUOTE_NONE)
output = map(mapper2, filter(filterer,map(mapper, reader)))
counts = counts+output
print "Emotion:" + emotion + " -- Processed " + str(counter) + "/" + str(len(glob.glob('*.csv'))) + " files"
counter+=1
dictionary = dict()
for (year, val) in counts:
dictionary[year] = dictionary.get(year, 0) + val # return the value for that key or return default 0 (and create key)
data_aggregated = [(key, val) for (key, val) in dictionary.iteritems()]
with open('pickledEmotions/'+ lang + '/' + emotion + '_'+ str.upper(lang) +'.pkl', 'w') as f:
pickle.dump([data_aggregated], f)
aggrEmotDic[emotion] = data_aggregated
os.chdir('..')
Great, we were able to extract all the emotion-related words from almost 20GB of data! Now we can compute means and z-scores (see this notebook for details) and visualize the results.
We can see evidence that emotion in literature reflects the general mood associated with historic events. Look, for instance, the drop in positive emotions during WW2. We also notice that positive vs negative emotions fluctuate in English literature, unlike German which is quite steady over time with few spikes.
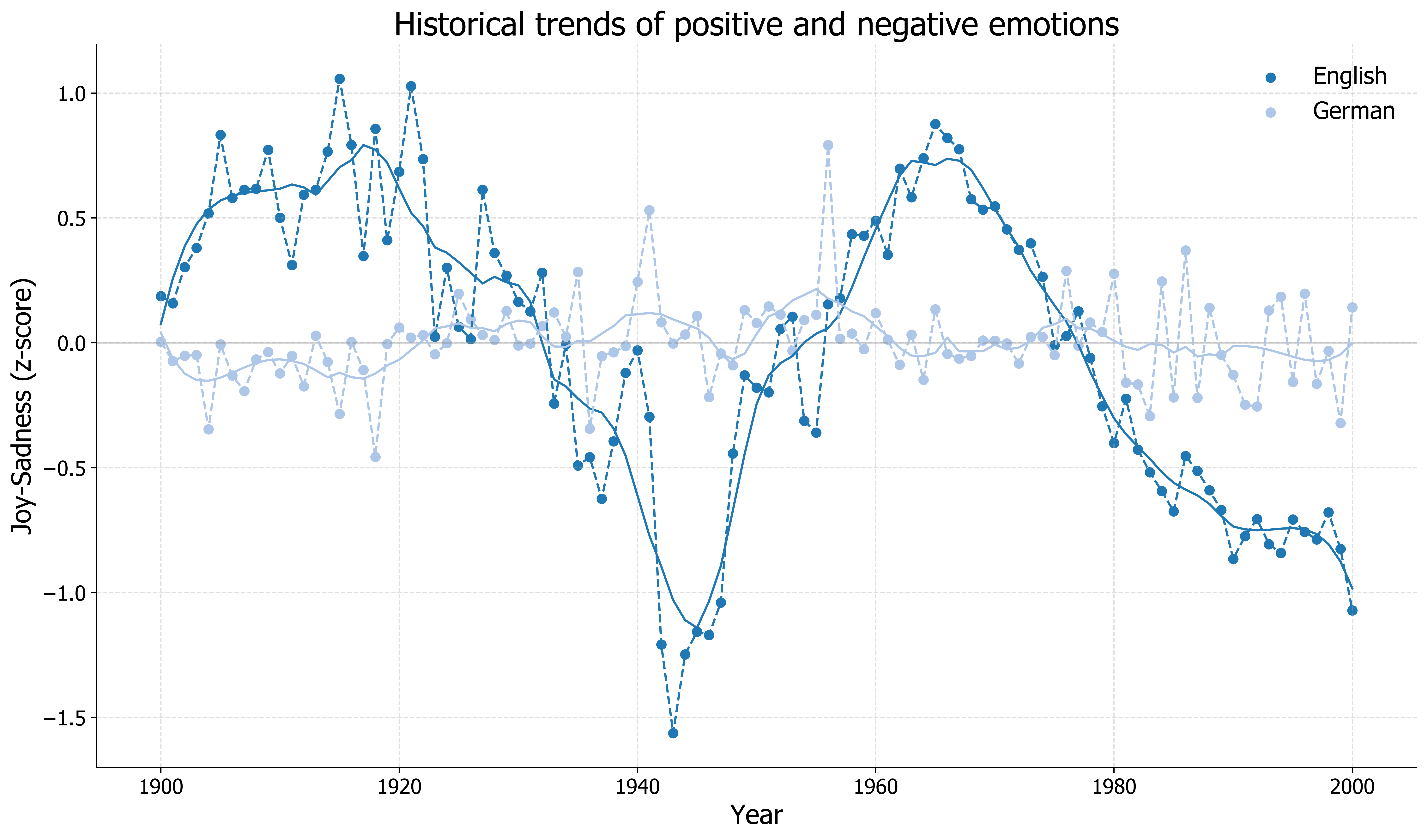
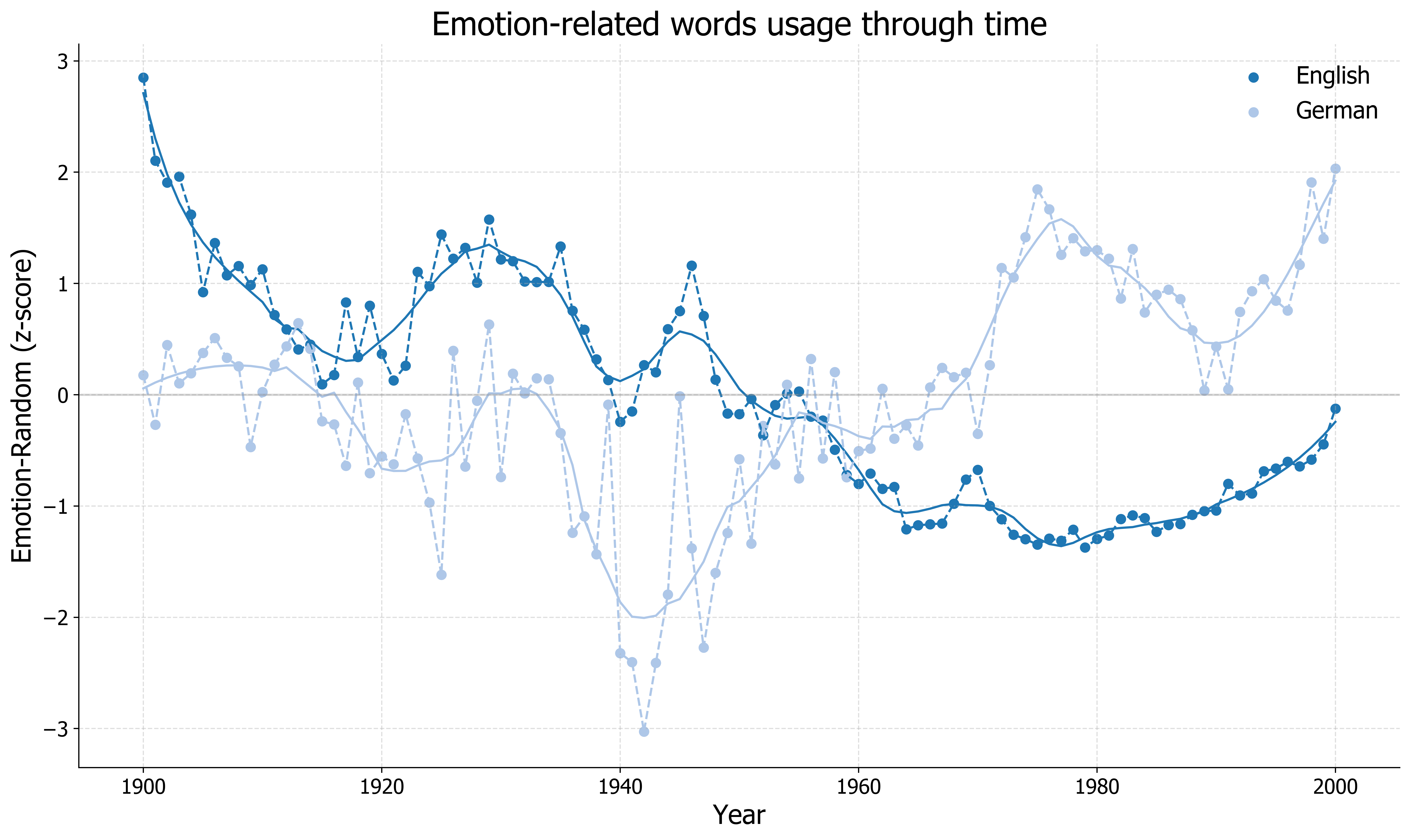
Another interesting finding is that the overall emotion-related word usage drops steadily through time for English literature. This is not the case for German literature, which shows increasing emotion usage, especially after the 1950s.
Finally, I plot a breakdown of z-scores for each emotion. A couple of interesting things here. Look at the spike in the fear-related words in German literature right after the end of WW2. Also, see how anger-related words increase in English literature during this period.
Summary
In this post I analyzed trends in the use of emotion-related words in literature. I show how to process large-scale text data in a computationally efficient manner.
Plotting the results reveals interesting associations between emotion and historical events, as well as differential patterns over time between English and German literature. You can find the full code in this GitHub repository.
Written on October 14th, 2018 by Sokratis Papadopoulos